反爬虫和反反爬虫?
从本章开始,我们将要进入反反爬虫篇的内容。
感觉如果是第一听到这个名字的读者肯定是懵逼的状态。现在我们先来介绍一下什么是爬虫、反爬虫、反反爬虫。
爬虫其实就是我们前面所学的代码,直接使用requests.get("http://xxx.com")就能拿到网站的源码。
但是很多时候,我们获取的都是有价值的数据,而网站开发者就不想让我们拿到他们的数据,就有了很多反爬虫的策略,不让我们那么容易的爬取到数据。反爬虫的策略其实其实主要就是三个方面:
- ①JS加密:Html是用js代码生成的,不让我们拿到html。
- ②禁IP:我们写爬虫的时候,一般用一个ip爬取,如果访问频率过高,网站开发者可以不让我们这个ip访问网站。
- ③验证码:获取数据之前要先输入验证码。
当然,除了这三个,还有些别的东西,比如说User-Agent识别这样的就属于比较基本的了,我们这里就不展开了。
而反反爬虫,其实就是针对上面的三个方面给出解决方案:
- ①针对JS加密:我们可以使用无头浏览器渲染js,再解析渲染后的html代码。
- ②针对禁IP:我们可以使用代理ip等方式,用不同的ip访问网站。
- ③针对验证码:我们可以对验证码进行识别,也可以使用云打码这种人工验证码平台。
关于爬虫、反爬虫、反反爬虫的故事,知乎上的这个回答描绘的非常形象。
如何应对网站反爬虫策略?如何高效地爬大量数据? - 申玉宝的回答 - 知乎
https://www.zhihu.com/question/28168585/answer/74840535
本章内容
通过上面的介绍,读者应该对反反爬虫有了一个基本的认识了。本章将要对反爬虫的第一个方案:JS加密,进行反反爬虫。
尝试爬取baidu.com
在介绍反反爬虫方法之前,我们先拿百度测试一下。这里假设我们想爬一爬百度搜索美女的搜索结果,也就是这个链接:https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3(注:这里URL进行了url编码)
我们先用之前超级好用的requests库试一下。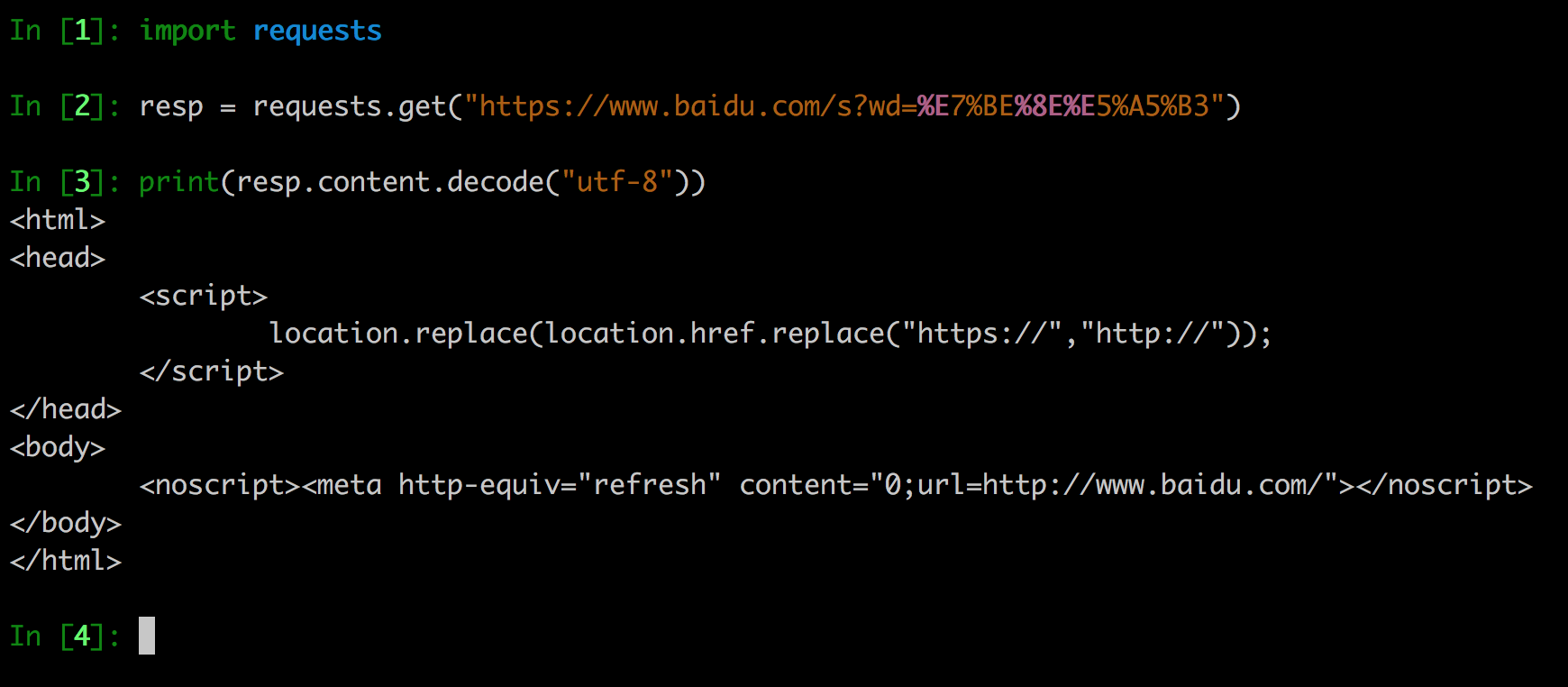
稍微懂点儿html的就知道,这里没看到所谓的美女图,反而还让我们跳转回http://www.baidu.com/。
什么是无头浏览器?
上面我们用requests.get什么都没看到,但我们用浏览器访问https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3的时候,的的确确看到了搜索结果的。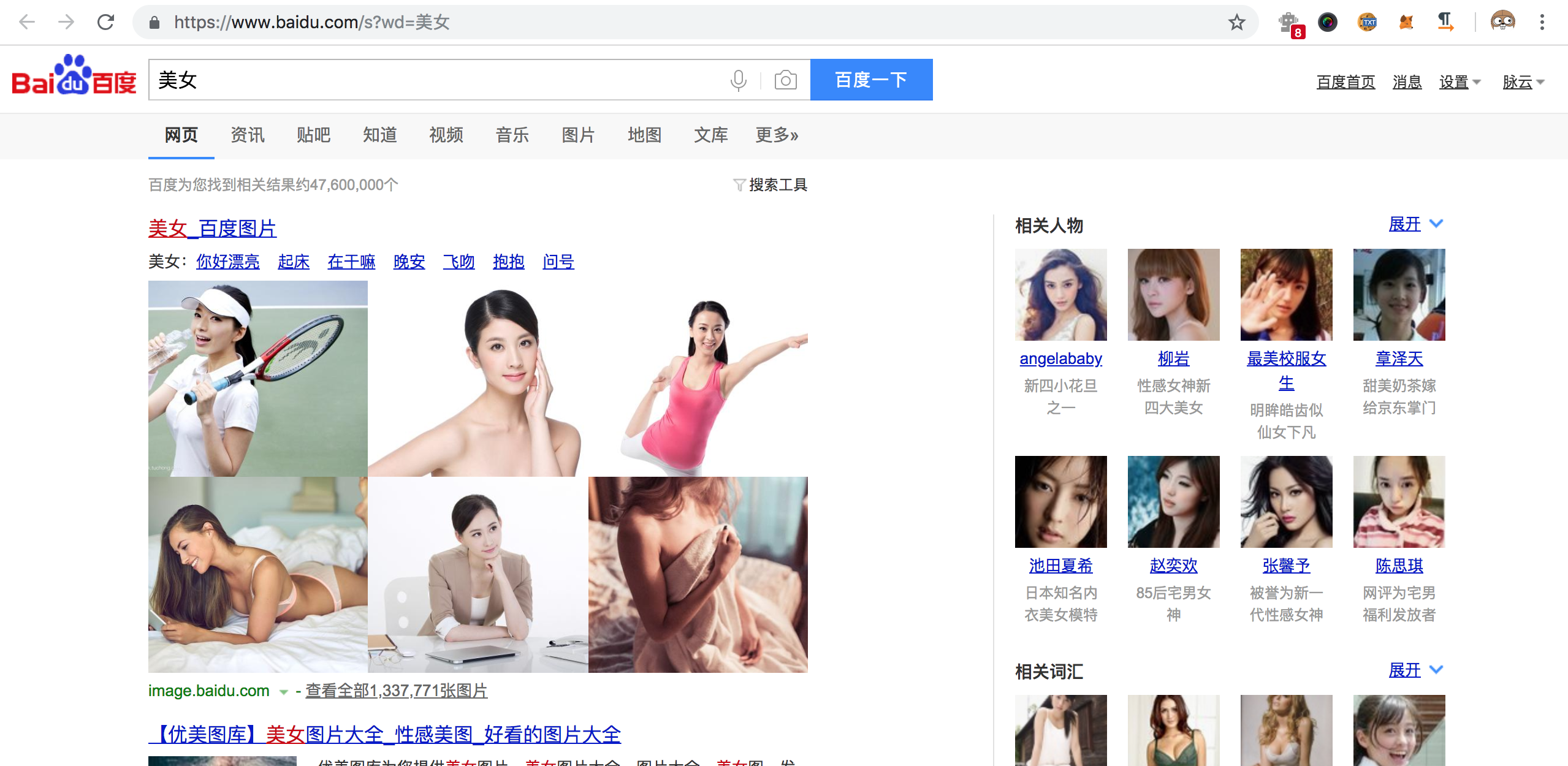
用requests不行,明显是百度的后台识别出来我们是低劣的爬虫程序,鄙视我们,什么都不给我们。
既然用浏览器可以,我们是不是可以通过Api调用我们的浏览器然后爬取搜索结果呢?
确实是可以,而且还有种浏览器叫:Headless Browser,也就是无头浏览器,没有界面的浏览器。如果有界面的话,我们可能还要用显卡去渲染图形页面,非常耗费字段,这简直是专门为爬虫开发者设计的。
Phantomjs
我们这里主要介绍的一款无头浏览器名叫:PhantomJS。虽然它现在已经不更新了,但不妨碍我们继续使用它。
下载PhantomJS
我们首先下载安装PhantomJS,下载链接为:http://phantomjs.org/download.html。
下载后解压可以看到在bin目录下面有一个phantomjs的可执行文件。(如果是windows的话就是phantomjs.exe)
安装selenium
接下来我们需要安装selenium,直接使用pip命令即可。
1 | pip install selenium |
selenium是一个用于Web应用程序测试的工具。它兼容各种浏览器,包括:PhantomJS、Chrome、FireFox等。
phantomjs默认的话要用JavaScript写代码。安装了selenium,我们就可以使用python进行操作了。
使用PhantomJS爬取百度
以上安装好了之后,我们再尝试使用phantomjs爬取一下百度。代码如下:
1 | from selenium import webdriver |
这里需要根据自己phantomjs的下载路径配置exe_path。然后首先创建一个driver对象,调用get访问页面,就会自动渲染内部的js,显示出结果。
注意:在不使用了之后,要调用driver.quit()退出,要不然后台会有很多phantomjs进程。
这里我们调用selenium的截图方法看下结果。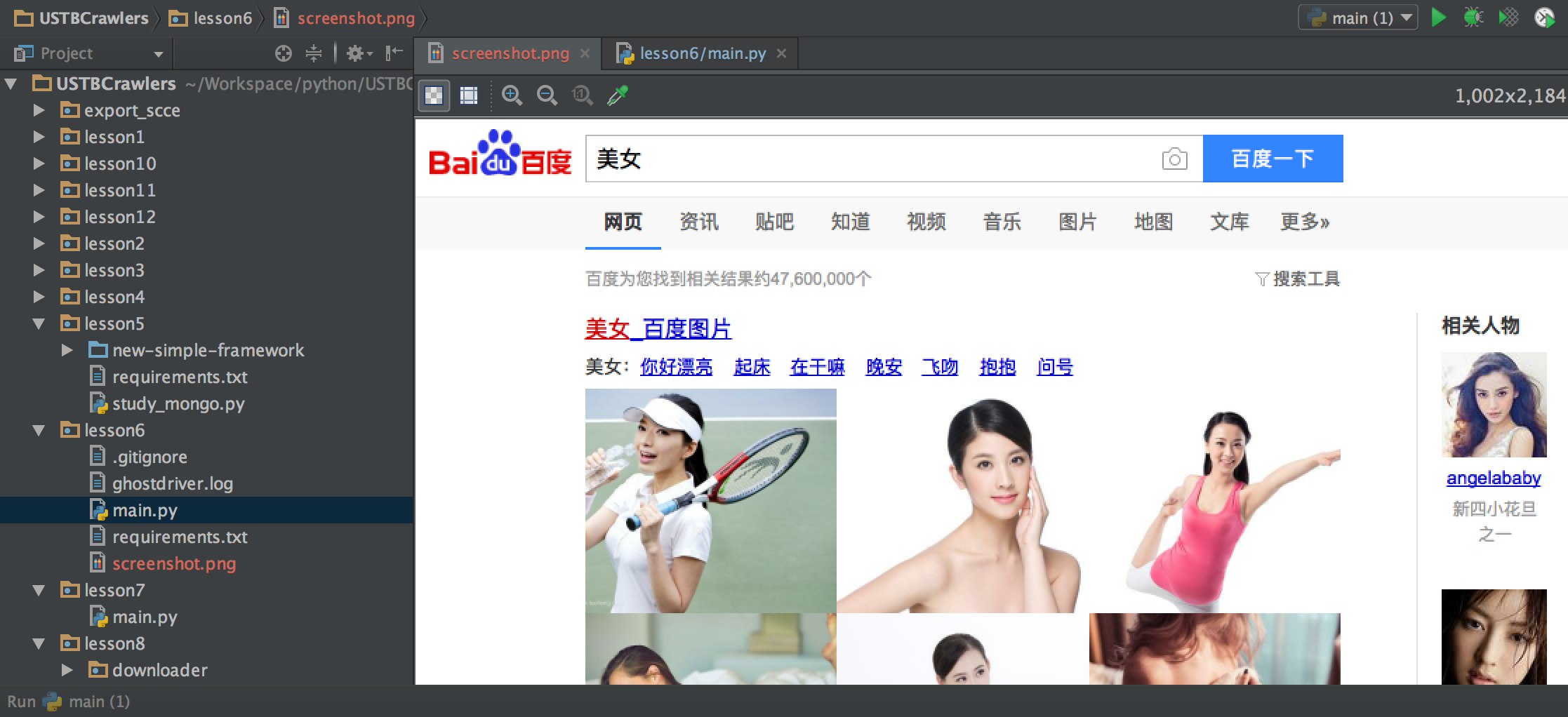
可以看到我们连网页的截图都弄出来了。selenium除了截图之外,还支持很多使用js才能完成的操作,比如说:模拟点击、滚动等等。如果读者感兴趣可以自己去研究。
修改PhantomJS的UA
PhantomJS默认的User-Agent使用的是:PhantomJS。如果我们带着这个会很容易被网站检测出来,我们可以在创建driver的时候加入配置修改PhantomJS的UA,让它伪装成Chrome浏览器。代码实现如下:
1 | from selenium import webdriver |
Chrome的无头模式
PhantomJS访客检测
当然,有的时候,你会发现有些网站你用了PhantomJS还是爬不了,笔者就遇到过这样的场景。这是因为PhantomJS建立在Qt框架。而Qt实现HTTP栈的方式使它和其他现代浏览器不一样。
在Chrome中,发出Http请求的head如下:
1 | GET / HTTP/1.1 |
然而在PhantomJS,相同的HTTP请求是这样的:
1 | GET / HTTP/1.1 |
你会注意到PhantomJS头是不同于Chrome(事实证明,其他所有现代浏览器)有一些微妙的不同:
- 主机(host) 出现最后一行
- 连接头(Connection)是大小写混合
- 唯一的 接受编码 值是gzip
在服务器上检查这些HTTP头的变化,它应该可以识别PhantomJS浏览器。
Selenium+Chrome
如果读者真的碰到这种情况的话,就可以考虑用别的无头浏览器了,比如说Chrome的无头模式。
Chrome的无头模式和selenium也可以结合在一起使用。这里首先需要下载chromedriver,然后通过selenium的API使用即可。以下为简单的示例,如果读者对这个感兴趣,可以查阅自行百度查找教程。
1 | from selenium import webdriver |
另一个工具:Splash
这里还有一款工具叫Splash,它是一个JavaScript渲染服务,基于Twisted和QT5,提供了Http的API。
相比PhantomJS和Chrome的无头模式,Splash的性能会好很多,而且可以支持并发渲染,不过需要跑Docker。
两个比较火的Python爬虫框架:Scrapy以及PySpider就是使用Splash作为JS渲染引擎。
这里笔者只是简单进行介绍,如果读者对这个感兴趣,可以查阅自行百度查找教程。